This is the multi-page printable view of this section. Click here to print.
Hardware
- 1: Architectural paremeters
- 2: Architecture diagram
- 3: Configuration registers
- 4: Instruction set
- 5: Performance samples
1 - Architectural paremeters
| Parameter | Description | Allowable values | Example value |
|---|---|---|---|
| Data type | The numerical format used to perform calculations in hardware | FP16BP8,FP32B16 |
FP16BP8, which means “Fixed point format with width 16 bits and with the binary point at 8 bits” |
| Array size | The size of the systolic array and also the number of scalars in each vector | 2-256 | 8 |
| DRAM0 depth | The number of vectors allocated in DRAM bank 0 | 2^{1-32} | 1048576 (= 2^20) |
| DRAM1 depth | The number of vectors allocated in DRAM bank 1 | 2^{1-32} | 1048576 (= 2^20) |
| Local depth | The number of vectors allocated in on-fabric main memory | 2^{1-16} | 16384 (= 2^14) |
| Accumulator depth | The number of vectors allocated in on-fabric accumulator memory | 2^{1-16} | 4096 (= 2^12) |
| SIMD registers depth | The number of registers to instantiate for each ALU in the SIMD module | 0-16 | 1 |
2 - Architecture diagram
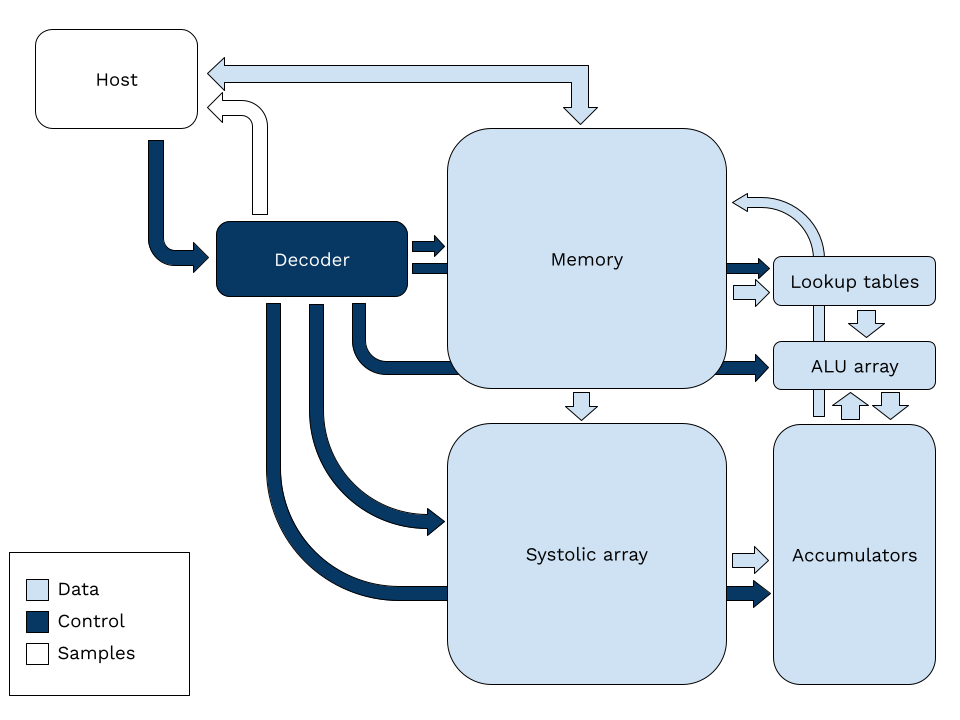
3 - Configuration registers
| Name | Meaning | Width (bits) | Number | Default value |
|---|---|---|---|---|
| DRAM0 address offset* | The offset in DRAM of the memory space allocated for use by the DRAM0 interface | 32 | 0x00 | 0x0000 |
| DRAM0 cache behaviour | This register is passed without modification to the AXI converter for the DRAM0 interface, where it is used as the value of the AxCACHE field in both reads and writes. Default value of 0b0000 indicates no caching allowed. See AXI4 protocol spec for more details. | 4 | 0x01 | 0b0000 |
| <unused> | - | - | 0x02-0x03 | - |
| DRAM1 address offset* | The offset in DRAM of the memory space allocated for use by the DRAM1 interface | 32 | 0x04 | 0x0000 |
| DRAM1 cache behaviour | This register is passed without modification to the AXI converter for the DRAM1 interface, where it is used as the value of the AxCACHE field in both reads and writes. Default value of 0b0000 indicates no caching allowed. See AXI4 protocol spec for more details. | 4 | 0x05 | 0b0000 |
| <unused> | - | - | 0x06-0x07 | - |
| Timeout | The number of cycles the decoder will remain in the same state before raising the timeout flag. This usually indicates something has stalled and is useful for triggering debug ILAs. | 16 | 0x08 | 0x0064 |
| Tracepoint | The value of the program counter at which the tracepoint flag will be raised. Useful for triggering debug ILAs to inspect hardware state during execution. | 32 | 0x09 | 0xFFFFFFFF |
| Program counter | Increments by 1 every time an instruction is completely processed. | 32 | 0x0A | 0x00000000 |
| Sample interval | The period in cycles at which to sample the program counter and decoder control bus handshake signals. Default value of 0x0000 disables sampling. | 16 | 0x0B | 0x0000 |
*DRAM address offsets are specified in 64K blocks. The real address offset is 2^16 times the address offset register value configured. That is, if the DRAMx address offset register is configured with value 0x0001, the actual address offset that will appear in requests on the AXI bus will be 0x00010000.
4 - Instruction set
| Name | Description | Opcode | Flags | Operand #0 | Operand #1 | Operand #2 |
|---|---|---|---|---|---|---|
| NoOp | Do nothing | 0x0 | - | - | - | - |
| MatMul | Load input at memory address into systolic array and store result at accumulator address | 0x1 | Accumulate? Zeroes? | Local Memory stride/address | Accumulator stride/address | Size |
| DataMove | Move data between the main memory and either the accumulators or one of two off-chip DRAMs | 0x2 | Data flow control enum (see below) | Local Memory stride/address | Accumulator or DRAM stride/address | Size |
| LoadWeight | Load weight from memory address into systolic array | 0x3 | Zeroes? (Ignores operand #0) | Local Memory stride/address | Size | - |
| SIMD | Perform computations on data in the accumulator | 0x4 | Read? Write? Accumulate? | Accumulator write address | Accumulator read address | SIMD sub-instruction |
| LoadLUT | Load lookup tables from memory address. | 0x5 | - | Local Memory stride/address | Lookup table number | - |
| <unused> | - | 0x6-0xE | - | - | - | - |
| Configure | Set configuration registers | 0xF | - | Register number | Value | - |
Notes
-
Weights should be loaded in reverse order
-
Since Size = 0 doesn’t make sense, the size argument is interpreted as 1 less than the size of data movement requested i.e.
- size = 0 means transfer 1 vector
- size = 1 means transfer 2 vectors
- size = 255 means transfer 256 vectors etc.
-
Instruction width is a parameter supplied to the RTL generator
- Opcode field is always 4 bits
- Flags field is always 4 bits
- Instruction must be large enough to fit the maximum values of all operands in the longest instruction (MatMul, DataMove, SIMD)
-
Flags are represented in the following order: [3 2 1 0]
- i.e. the first flag listed is at bit 0 (the 4th bit), second flag is at bit 1 (the 3rd bit) etc.
-
Arguments are in the following order: [2 1 0]
-
e.g. in MatMul the bits of the instruction will be, from most significant bit to least: opcode, optional zero padding, accumulate?, size, accumulator stride/address, memory stride/address
-
Address unit for all memories is one array vector
-
Stride has a fixed number of bits followed by the number of bits for the address of the largest memory that may appear in the operand. The address for smaller memories gets padded by zeros. Stride is encoded as power of 2. For example the 3-bit stride is as follows 000=1, 001=2, 010=4, 011=8,.. 111=128
-
e.g. in a 2-byte argument with an 11-bit address and a 3-bit stride, the bit layout would be
- 15:14 = padding, to be set to zeroes
- 13:11 = stride
- 10:0 = address
-
-
Size unit is one array vector
-
-
Data flow control enum flag values are:
- 0b0000 = 0 = 0x0 = DRAM0 to memory
- 0b0001 = 1 = 0x1 = memory to DRAM0
- 0b0010 = 2 = 0x2 = DRAM1 to memory
- 0b0011 = 3 = 0x3 = memory to DRAM1
- …
- 0b1100 = 12 = 0xc = accumulator to memory
- 0b1101 = 13 = 0xd = memory to accumulator
- 0b1110 = 14 = 0xe = <reserved>
- 0b1111 = 15 = 0xf = memory to accumulator (accumulate)
-
SIMD instructions have some subtleties
-
can read or write (+accumulate) in the same instruction
-
when the read flag is set, data is read from the accumulators into the ALU array
-
when the write flag is set, the ALU array output is written into the accumulators
-
the accumulate flag determines whether this is an accumulate or an overwrite
-
the output to be written is computed from the input that was read in on the same instruction
- i.e. if `x` is read from the accumulators at the specified read address, and the ALU computes `f(_)` then `f(x)` will be written to the accumulators at the specified write address from the same instruction
-
data is output from the ALU array on every instruction i.e. even if the destination is specified as register 1, you can still write into the accumulators from the output
-
-
before reading out from the accumulators with a DataMove, you should wait at least 2 instructions since the last SIMD instruction in which the write flag was high. This is because the data takes about 2 instructions to propagate into the accumulators from the ALUs. The easiest way to achieve this is just to insert 2 no-ops before the DataMove instruction.
- 2 instructions is an empirical estimate. The number may need to be higher in certain cases. If you see data being dropped/corrupted/repeated, talk to[email protected] about it
-
SIMD sub-instructions
All SIMD instructions are composed of 4 parts: opcode, source left, source right and destination. The widths are as follows:
-
opcode = ceil(log2(numOps))
- numOps is currently fixed at 16, so opcode is 4 bits
-
source left = ceil(log2(numRegisters+1))
- numRegisters is currently fixed at 1, so source left is 1 bit
-
source right = source left
-
dest = source left
Source left is the left argument for binary operations, and the single argument for unary operations. Source right is the right argument for binary operations, and is ignored for unary operations.
The_Move_ opcode allows you to move data from one register to another, or to read the data in a register to output. The _NoOp_ opcode is only a true no-op when both the read and write flags are set to false in the SIMD instruction. Otherwise, _NoOp_ has an overloaded meaning: it is used to trigger an external read or write. That is, to write into the accumulators from the PE array, or to read out from the accumulators into on-chip main memory.
| Opcode | Source left | Source right | Destination |
|---|---|---|---|
| 0x00 = NoOp** 0x01 = Zero 0x02 = Move* 0x03 = Not* 0x04 = And 0x05 = Or 0x06 = Increment* 0x07 = Decrement* 0x08 = Add 0x09 = Subtract 0x0A = Multiply 0x0B = Abs* 0x0C = GreaterThan 0x0D = GreaterThanEqual 0x0E = Min 0x0F = Max 0x10 = Lookup* |
0 = input 1 = register 1 2 = register 2… |
0 = input 1 = register 1 2 = register 2… |
0 = output 1 = output & register 1 2 = output & register 2… |
*unary operation
**arguments are ignored
Lookup sub-instruction
The lookup sub-instruction returns_N+1_ result values where _N_ is the number of lookup tables in the architecture. The results are, in order
- the difference between the argument and the closest key found in the lookup table index
- the value found in the first lookup table
- the value found in the second lookup table
- etc.
The destination register_d_specifies the register which will receive the first result i.e. the difference. The remaining results will be populated in the registers numbered ascending from_d_, so that the result from lookup table_i_ will be written to register _d+i+1_. This assumes that the architecture is configured with sufficient registers to store all the results, and that_d+N_ <= total number of registers. The behaviour of the lookup sub-instruction is undefined if these requirements aren’t met.
5 - Performance samples
Performance sampling
The program counter and decoder control bus handshake signals can be sampled at a fixed interval of L cycles in order to measure system performance. The samples are written out to the sample IO bus in blocks of N sample words. The block is terminated by asserting the AXI stream TLAST signal. Each sample word is a 64-bit word, with the following meaning:
| Bus name | Signal | Bit field(s) | Comments |
|---|---|---|---|
| Program counter | 0:31 | Contains all 1s if the sample is invalid. Invalid samples are produced when the sampling interval is set to 0. | |
| Array | Valid | 32 | Contains all 0s if the sample is invalid. |
| Ready | 33 | ||
| Acc | Valid | 34 | |
| Ready | 35 | ||
| Dataflow | Valid | 36 | |
| Ready | 37 | ||
| DRAM1 | Valid | 38 | |
| Ready | 39 | ||
| DRAM0 | Valid | 40 | |
| Ready | 41 | ||
| MemPortB | Valid | 42 | |
| Ready | 43 | ||
| MemPortA | Valid | 44 | |
| Ready | 45 | ||
| Instruction | Valid | 46 | |
| Ready | 47 | ||
| <unused> | 48:64 |
Value of L can be changed by setting the configuration register. Value of N is defined by architecture.